charm AT lists.cs.illinois.edu
Subject: Charm++ parallel programming system
List archive
- From: Aditya Kiran Pandare <apandar AT ncsu.edu>
- To: charm AT lists.cs.illinois.edu
- Subject: [charm] Using Load balancers in charm++
- Date: Tue, 12 Sep 2017 18:11:52 -0400
- Authentication-results: illinois.edu; spf=none smtp.mailfrom=apandar AT ncsu.edu
Hello,
I'm a graduate student from NC State University and am new to parallel programming and the charm++ environment. I'm working on using charm to parallelize a Mandelbrot set calculation. I was able to do this without load balancing; so the next step is trying to use a load balancer, specifically DistributedLB. I'm currently trying the "periodical load balancing mode". I was hoping to get some help from this mailing-list about a few questions I have.
The problem I'm facing is that, even when I use a load balancer, I don't see any change in the PE usage (as compared to no load balancer). I've attached the timelines for the case with and without DistributedLB for comparison (timeline_distLB.pdf, timeline_noLB.pdf). I'm trying to debug my code to find the reason why I cannot see any effect of load balancing. I have a hunch that the chares are not getting migrated at all. I
have attached the screen outputs when I run with and without the load
balancer (DistLB.log, NoLB.log). As you can see, I have run with the +cs
flag.
My questions:
1) Is there a way to check chare-migration in charm++?
2) In this test, the number of chares are 40 (as seen in the "Load distribution" screen output). However, the "Total chares" shows only 12 created. Could you explain how I can interpret this?
3) Also if we compare the outputs of the two tests, it can be seen that there are differences in the "mesgs for groups" column of the statistics table. Does this mean that Load Balancing is actually being used by the code, but in an incorrect way?
To make sure I got the compilation, etc. right, here's how I proceeded:
First, I compiled & linked the code with the "-module CommonLBs". Now, I'm trying to run the code on 8 cores of a single node.
Then, the command I used to run the code: ./charmrun +p8 ./mandel 4000 0.8 +cs +balancer DistributedLB +LBPeriod 1.0
(here the ./mandel takes two arguments, int and double)
Any help is appreciated.
Thank you,
--
Aditya K Pandare
Graduate Research Assistant
Computational Fluid Dynamics Lab A
3211, Engineering Building III
Department of Mechanical and Aerospace Engineering (MAE)
North Carolina State University
Running on 8 processors: ./mandel 4000 0.8 +cs
charmrun> /usr/bin/setarch x86_64 -R mpirun -np 8 ./mandel 4000 0.8 +cs
Charm++> Running on MPI version: 3.0
Charm++> level of thread support used: MPI_THREAD_SINGLE (desired: MPI_THREAD_SINGLE)
Charm++> Running in non-SMP mode: numPes 8
Converse/Charm++ Commit ID:
Charm++: Tracemode Projections enabled.
Trace: traceroot: ./mandel
Warning> Randomization of stack pointer is turned on in kernel, thread migration may not work! Run 'echo 0 > /proc/sys/kernel/randomize_va_space' as root to disable it, or try run with '+isomalloc_sync'.
CharmLB> Load balancer assumes all CPUs are same.
Charm++> Running on 1 unique compute nodes (32-way SMP).
Charm++> cpu topology info is gathered in 0.001 seconds.
------------------------------------------------------
Width in Pixels : 4000
Number of PEs : 8
Virtualization : 0.800000
Chunksize : 100
Remainder : 0
Load distribution: 40 (39*100+100)
------------------------------------------------------
Computation time: 11.170000 .
------------------------------------------------------
Charm Kernel Summary Statistics:
Proc 0: [12 created, 12 processed]
Proc 1: [0 created, 0 processed]
Proc 2: [0 created, 0 processed]
Proc 3: [0 created, 0 processed]
Proc 4: [0 created, 0 processed]
Proc 5: [0 created, 0 processed]
Proc 6: [0 created, 0 processed]
Proc 7: [0 created, 0 processed]
Total Chares: [12 created, 12 processed]
Charm Kernel Detailed Statistics (R=requested P=processed):
Create Mesgs Create Mesgs Create Mesgs
Chare for Group for Nodegroup for
PE R/P Mesgs Chares Mesgs Groups Mesgs Nodegroups
---- --- --------- --------- --------- --------- --------- ----------
0 R 12 0 14 29 0 0
P 12 0 14 13 0 0
1 R 0 0 0 5 0 0
P 0 0 14 11 0 0
2 R 0 0 0 5 0 0
P 0 0 14 11 0 0
3 R 0 0 0 5 0 0
P 0 0 14 8 0 0
4 R 0 0 0 5 0 0
P 0 0 14 5 0 0
5 R 0 0 0 5 0 0
P 0 0 14 5 0 0
6 R 0 0 0 5 0 0
P 0 0 14 5 0 0
7 R 0 0 0 5 0 0
P 0 0 14 5 0 0
[Partition 0][Node 0] End of program
Running on 8 processors: ./mandel 4000 0.8 +cs +balancer DistributedLB +LBPeriod 1.0
charmrun> /usr/bin/setarch x86_64 -R mpirun -np 8 ./mandel 4000 0.8 +cs +balancer DistributedLB +LBPeriod 1.0
Charm++> Running on MPI version: 3.0
Charm++> level of thread support used: MPI_THREAD_SINGLE (desired: MPI_THREAD_SINGLE)
Charm++> Running in non-SMP mode: numPes 8
Converse/Charm++ Commit ID:
Charm++: Tracemode Projections enabled.
Trace: traceroot: ./mandel
Warning> Randomization of stack pointer is turned on in kernel, thread migration may not work! Run 'echo 0 > /proc/sys/kernel/randomize_va_space' as root to disable it, or try run with '+isomalloc_sync'.
CharmLB> Load balancer assumes all CPUs are same.
Charm++> Running on 1 unique compute nodes (32-way SMP).
Charm++> cpu topology info is gathered in 0.001 seconds.
[0] DistributedLB created
------------------------------------------------------
Width in Pixels : 4000
Number of PEs : 8
Virtualization : 0.800000
Chunksize : 100
Remainder : 0
Load distribution: 40 (39*100+100)
------------------------------------------------------
Computation time: 11.170000 .
------------------------------------------------------
[0] In DistributedLB strategy
Charm Kernel Summary Statistics:
Proc 0: [12 created, 12 processed]
Proc 1: [0 created, 0 processed]
Proc 2: [0 created, 0 processed]
Proc 3: [0 created, 0 processed]
Proc 4: [0 created, 0 processed]
Proc 5: [0 created, 0 processed]
Proc 6: [0 created, 0 processed]
Proc 7: [0 created, 0 processed]
Total Chares: [12 created, 12 processed]
Charm Kernel Detailed Statistics (R=requested P=processed):
Create Mesgs Create Mesgs Create Mesgs
Chare for Group for Nodegroup for
PE R/P Mesgs Chares Mesgs Groups Mesgs Nodegroups
---- --- --------- --------- --------- --------- --------- ----------
0 R 12 0 14 49 0 0
P 12 0 14 21 0 0
1 R 0 0 0 14 0 0
P 0 0 14 20 0 0
2 R 0 0 0 10 0 0
P 0 0 14 19 0 0
3 R 0 0 0 10 0 0
P 0 0 14 14 0 0
4 R 0 0 0 8 0 0
P 0 0 14 8 0 0
5 R 0 0 0 16 0 0
P 0 0 14 11 0 0
6 R 0 0 0 14 0 0
P 0 0 14 10 0 0
7 R 0 0 0 16 0 0
P 0 0 14 11 0 0
[Partition 0][Node 0] End of program
Attachment:
timeline_noLB.jpg
Description: JPEG image
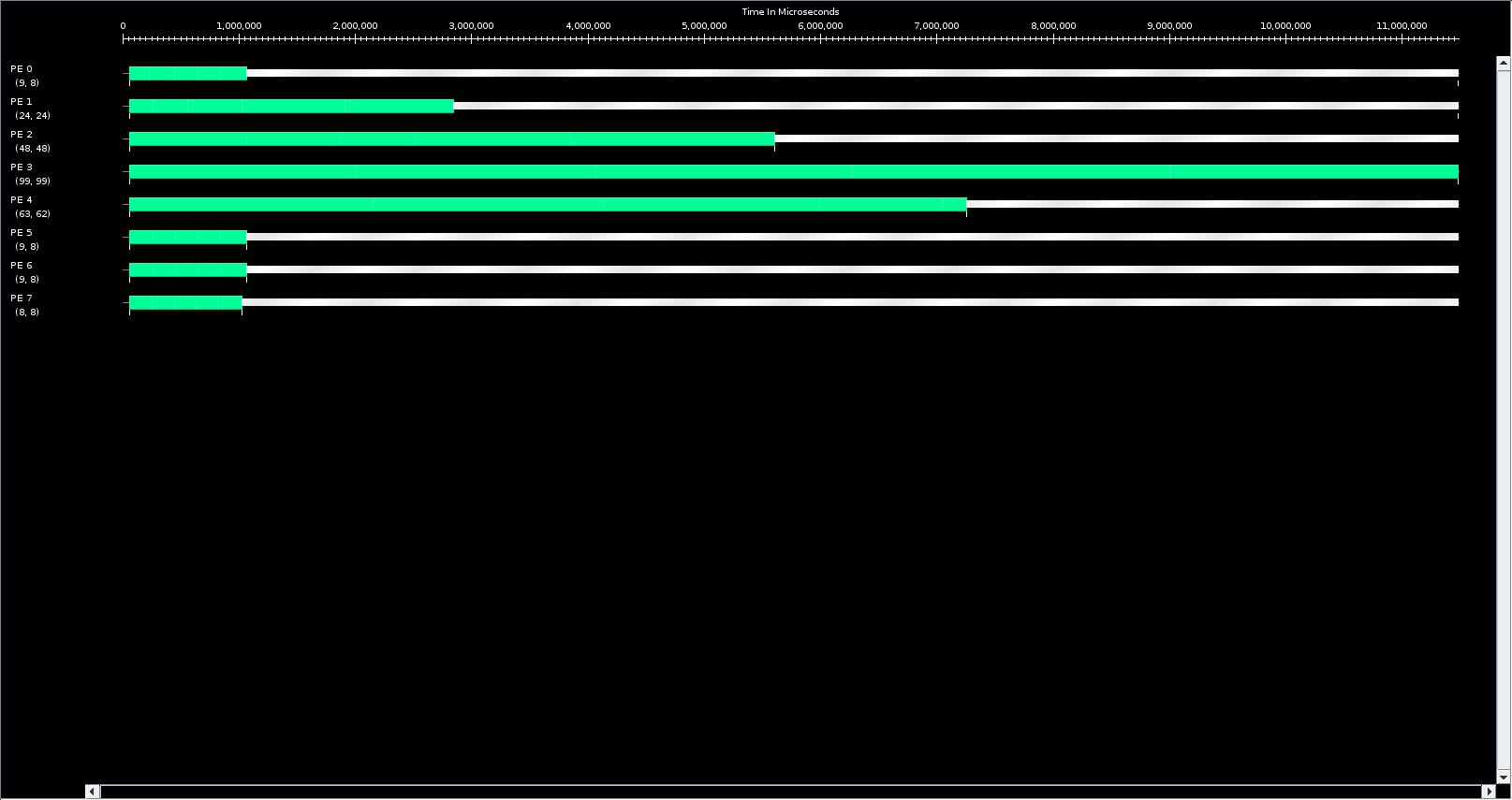{kind=link}
Attachment:
timeline_distLB.jpg
Description: JPEG image
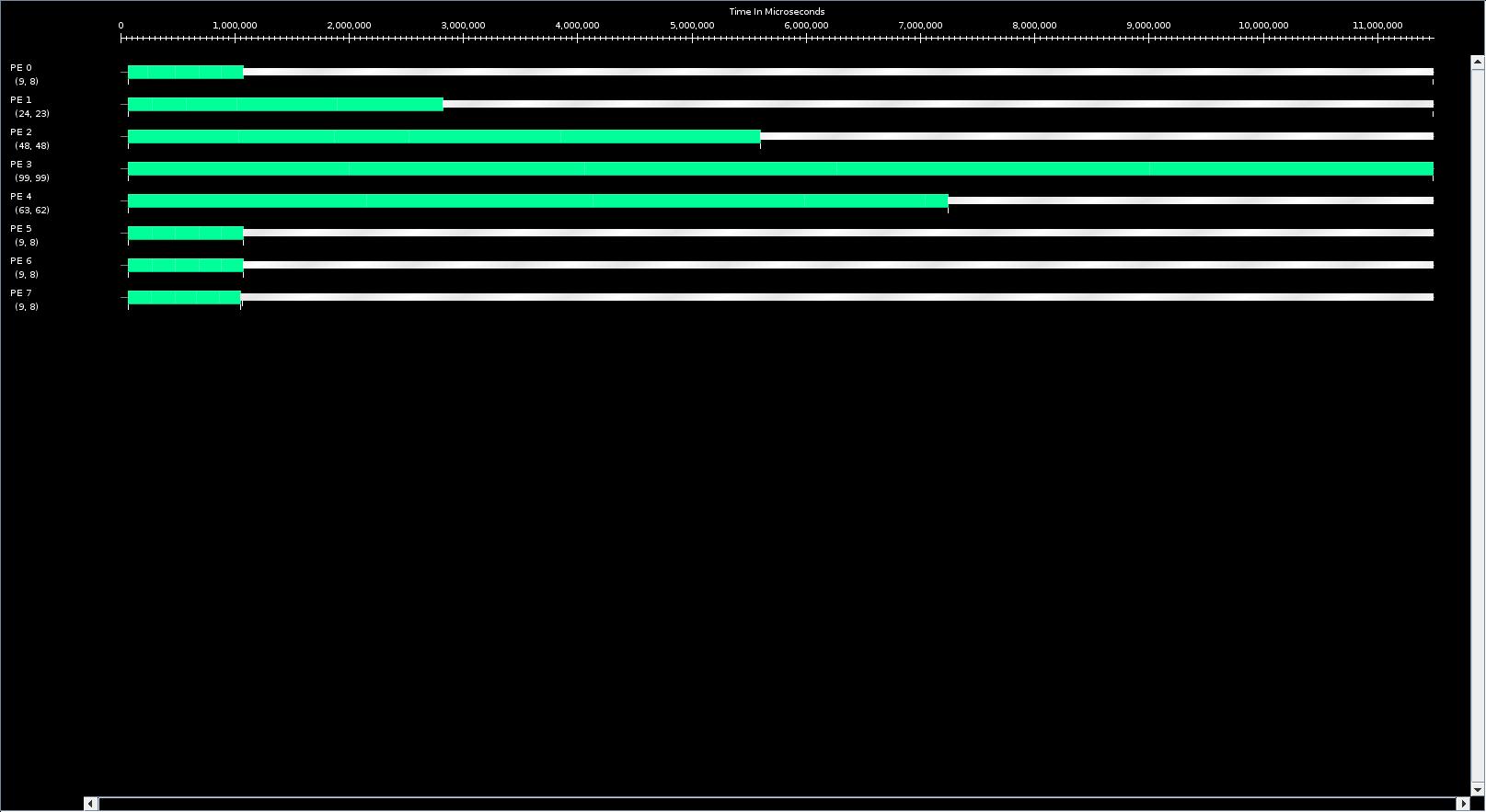{kind=link}
- [charm] Using Load balancers in charm++, Aditya Kiran Pandare, 09/12/2017
- Re: [charm] Using Load balancers in charm++, Laércio Lima Pilla, 09/12/2017
- Re: [charm] Using Load balancers in charm++, Aditya Kiran Pandare, 09/12/2017
- Re: [charm] Using Load balancers in charm++, Vinicius Freitas, 09/12/2017
- Re: [charm] Using Load balancers in charm++, Aditya Kiran Pandare, 09/13/2017
- Re: [charm] Using Load balancers in charm++, Laércio Lima Pilla, 09/13/2017
- Re: [charm] Using Load balancers in charm++, Kale, Laxmikant V, 09/13/2017
- Re: [charm] Using Load balancers in charm++, Aditya Kiran Pandare, 09/13/2017
- Re: [charm] Using Load balancers in charm++, Aditya Kiran Pandare, 09/13/2017
- <Possible follow-up(s)>
- Re: [charm] Using Load balancers in charm++, Aditya Kiran Pandare, 09/16/2017
- Re: [charm] Using Load balancers in charm++, Laércio Lima Pilla, 09/12/2017
Archive powered by MHonArc 2.6.19.