charm AT lists.cs.illinois.edu
Subject: Charm++ parallel programming system
List archive
- From: Dan Kokron <dkokron AT gmail.com>
- To: charm AT cs.illinois.edu
- Subject: [charm] Optimization
- Date: Wed, 26 Aug 2020 10:22:42 -0500
- Authentication-results: illinois.edu; spf=softfail smtp.mailfrom=dkokron AT gmail.com; dkim=pass header.s=20161025 header.d=gmail.com; dmarc=pass header.from=gmail.com
I am working with some researchers who are running some COVID19 simulations using NAMD. I have performed an extensive search of the parameter space trying to find the best performance for their case. I am asking this question here because the performance of this case depends greatly on communication.
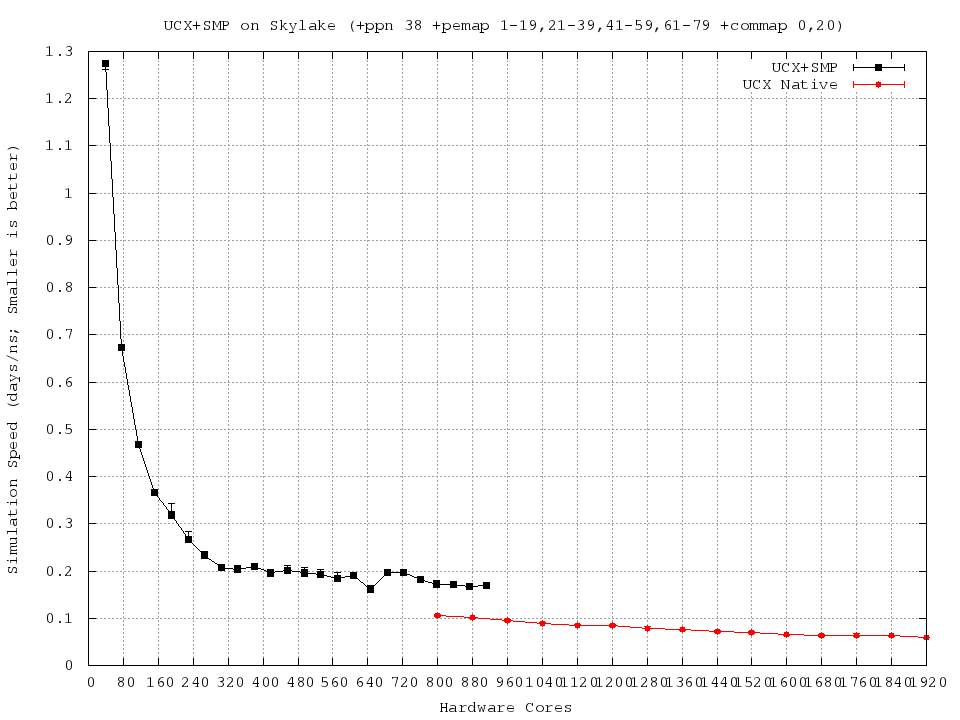
Eric Bohm suggested that UCX+SMP would provide the best scaling yet that configuration (or my use of it) falls significantly behind native UCX. See attached.
Hardware:
multi-node Xeon (skylake), each node has 2 Gold 6148 (40 hardware cores with HT enabled)
nodes are connected with EDR Infiniband
Software:
NAMD git/master
CHARM++ 6.10.2
HPCX 2.7.0 (OpenMPI + UCX-1.9.0)
Intel 2019.5.281 compiler
CHARM++ for the UCX+SMP build was built with
setenv base_charm_opts "-O3 -ip -g -xCORE-AVX512"
./build charm++ ucx-linux-x86_64 icc ompipmix smp --suffix avx512 --with-production $base_charm_opts --basedir=$HPCX_UCX_DIR --basedir=$HPCX_MPI_DIR -j12
The native UCX build was the same except without the 'smp' option.
The UCX+SMP build of NAMD was built with
FLOATOPTS = -ip -O3 -xCORE-AVX512 -qopt-zmm-usage=high -fp-model fast=2 -no-prec-div -qoverride-limits -DNAMD_DISABLE_SSE -qopenmp-simd -DNAMD_AVXTILES
./config Linux-x86_64-icc --charm-arch ucx-linux-x86_64-ompipmix-smp-icc-avx512 --with-fftw3 --fftw-prefix /fftw-3.3.8/install/namd --charm-opts -verbose
Simulation Case:
1764532 atoms (See attached output listing)
UCX+SMP launch
mpiexec -np $nsockets --map-by ppr:1:socket --bind-to core -x UCX_TLS="rc,xpmem,self" /Linux-x86_64-icc-ucx-smp-xpmem-avx512/namd2 +ppn 38 +pemap 1-19,21-39,41-59,61-79 +commap 0,20 +setcpuaffinity +showcpuaffinity restart.namd
Would you expect native UCX to outperform UCX_SMP in this scenario?
Can you suggest some ways to improve the performance of my UCX+SMP build?
Dan
Attachment:
NAMD_UCX+SMP_vs_Native_UCX.png
Description: PNG image
{kind=link}
Attachment:
skxOnskx.UCX.XPMEM.SMP.48s
Description: Binary data
- [charm] Optimization, Dan Kokron, 08/26/2020
- Re: [charm] Optimization, Bohm, Eric J, 08/27/2020
- Re: [charm] Optimization, Dan Kokron, 08/27/2020
- Re: [charm] Optimization, Dan Kokron, 08/27/2020
- Re: [charm] Optimization, Dan Kokron, 08/27/2020
- Re: [charm] Optimization, Kale, Laxmikant V, 08/27/2020
- Re: [charm] Optimization, Dan Kokron, 08/27/2020
- Re: [charm] Optimization, Bohm, Eric J, 08/27/2020
Archive powered by MHonArc 2.6.19.