charm AT lists.cs.illinois.edu
Subject: Charm++ parallel programming system
List archive
- From: Sam White <white67 AT illinois.edu>
- To: "Van Der Wijngaart, Rob F" <rob.f.van.der.wijngaart AT intel.com>
- Cc: "Kale, Laxmikant V" <kale AT illinois.edu>, "Chandrasekar, Kavitha" <kchndrs2 AT illinois.edu>, "charm AT cs.uiuc.edu" <charm AT cs.uiuc.edu>
- Subject: Re: [charm] When to migrate
- Date: Wed, 21 Dec 2016 15:20:07 -0600
./charmrun +p2 /usr/bin/valgrind --tool=memcheck --leak-check=yes -v --log-file=myvalg_txt.%p --trace-children=yes ./pgm +vp1 +balancer RotateLB ++local
For the array that gets overwritten after migration, you are still pup'ing the size of that array, deleting it when the pup_er is deleting and allocating it to the right size when unpacking right? It often helps when debugging PUP routines to print out what stage the pup_er is in (sizing, packing, unpacking, deleting) and check whatever values you are interested in at each stage.
Also, we merged a fix earlier today for issues in startup for Isomalloc on multicore-linux64 and netlrts-linux-x86_64-smp builds. If you are using one of those builds I would recommend doing a 'git pull origin charm' first, otherwise you might see a hang during initialization. There has not been a 6.8.0 release candidate yet, since there are still a couple bugs left that need to be fixed.
-Sam
Hi Sam,
I have a new question. I am getting good results with PUPing on Edison, except I need to PUP a certain array whose values after migration are overwritten. That is wasteful, but if I don’t do it, I get erroneous answers. You’d think the error must be on my side, but I cannot find it. And there is only so much that an application programmer can do to debug a faulty PUP routine. Of course, it I well possible that I have a bug in my plain MPI code, which does not trigger errors there, but wreaks havoc in an AMPI context. I unleashed valgrind on my code, which produced no memory errors (except a leak in MPI_Init itself, and that can be safely ignored). Next, I tried valgrind on the AMPI version, but that hangs. I went to the documentation and specified --log-file=VG.out.%p --trace-children=yes. I do get tracefiles, strangely, and these say there are no errors, but the code never finishes. Is this a known bug, and are there workarounds? Also, has there been a 6.8 Charm++ release that I should try first? Thanks!
Rob
From: Van Der Wijngaart, Rob F
Sent: Thursday, December 08, 2016 6:38 PM
To: Sam White <white67 AT illinois.edu>
Cc: Kale, Laxmikant V <kale AT illinois.edu>; Chandrasekar, Kavitha <kchndrs2 AT illinois.edu>
Subject: RE: [charm] When to migrate
Thanks, Sam. Yes, I did get SMP mode working on Edison with srun. It was my bad.
Maybe I’ll try without comm processes first and then play around with some variations. There is an additional reason why I want a decent factorization of the number of compute cores per node. 24 or 20 both give that, but my code is not very communication intensive (it’s derived from the Stencil Parallel Research Kernel, if that means anything to you), so giving up 4 cores for comms seems excessive. With a decent factorization I can arrange my code so that no communications are required for the adaptive refinements that show up from time to time (except for load rebalancing), which makes my experiments much cleaner than otherwise.
Rob
From: samt.white AT gmail.com [mailto:samt.white AT gmail.com] On Behalf Of Sam White
Sent: Thursday, December 08, 2016 5:30 PM
To: Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com>
Cc: Kale, Laxmikant V <kale AT illinois.edu>; Chandrasekar, Kavitha <kchndrs2 AT illinois.edu>
Subject: Re: [charm] When to migrate
That depends on the application: what the ratio of on-node/off-node communication is, how much communication there is, how spread out over time its network injection is, does the program itself take advantage of Charm++'s shared memory features, etc.
It is not uncommon that an application performs best in SMP mode with multiple processes per physical node though. This is most often due to NUMA domain effects or communication intensity (the comm thread can become a serial bottleneck). You will have to experiment with your application to be sure. For SMP mode you could try 2 or 4 processes per node, giving you 22 or 20 worker thread per node.
Also, did you figure out the srun commands to get SMP mode runs working on Edison?
-Sam
On Thu, Dec 8, 2016 at 7:02 PM, Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com> wrote:
Hi Sam,
One more question, how much of an impact does reserving one core per compute node have on performance? I am looking at 2D grids that need to be divided among a number of ranks. On my SMP workstation I have 36 cores, and since I don’t need to reserve a communication core there, I can decompose my discretization grid among a 6x6 processor grid (with overdecomposition the factors change, of course). On Edison I have 24 cores per node. Minus one for communication means 23 cores left, which is prime, so I’ll end up with a 1D decomposition of my domain (1x23 processor grid). With 24 cores it would be 4x6, so much more benign. Thanks!
Rob
From: samt.white AT gmail.com [mailto:samt.white AT gmail.com] On Behalf Of Sam White
Sent: Thursday, December 08, 2016 11:01 AM
To: Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com>
Cc: Kale, Laxmikant V <kale AT illinois.edu>; Chandrasekar, Kavitha <kchndrs2 AT illinois.edu>
Subject: Re: [charm] When to migrate
Hi Rob,
First, I found an ancient issue in AMPI's Load_{start,stop}_measure routines where AMPI was not actually turning on/off the LB Database's collecting of statistics, and we pushed it to mainline charm this morning. That is now fixed so if you do a 'git pull origin charm' in your charm directory you should get the update.
Second, we test Charm++ and AMPI nightly on Edison. You can build it like this (on GCC or ICC):
$ module load craype-hugepages8M
$ ./build AMPI gni-crayxc -j8 --with-production
Then when linking an AMPI program with Isomalloc you should add '-Wl,--allow-multiple-definition' on Edison. (We should be able to automate the addition of that flag in ampicc by our next release.)
Edison has 24 cores/node, so to run a program on 2 nodes launching 48 processes, do:
$ srun -n 48 ./pgm +vp512 +isomalloc_sync
Charm++/AMPI can be built to run in SMP mode, where one thread/core is dedicated to the runtime's communication needs. SMP mode is often beneficial to performance at large scales. You can try this build by doing:
$ ./build AMPI gni-crayxc smp -j8 --with-production
Then you compile your program in the same way, but when you run you'll need to specify the mappings of threads to cores:
$ srun -n 2 -c 24 ./pgm +vp512 ++ppn 24 +commap 0 +pemap 1-23 +isomalloc_sync
That runs with 23 worker threads per node and 1 communication thread per node, over 2 nodes (in total, 46 worker threads). We have changes to the runtime coming that will make launching SMP jobs much simpler in the future.
I can't actually get a job through the queue right now on Edison to validate the exact run commands I've given, so if they don't work let me know.
-Sam
On Thu, Dec 8, 2016 at 10:40 AM, Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com> wrote:
Hi Sanjay,
I have finished my AMPI runs on my shared-memory workstation and am now moving to NERSC’s Edison. Does your team have any recommendations for compiling and running AMPI codes on that system? I think you normally recommend reserving one core per node for runtime duties, right? A sample representative Makefile and run script would be really nice.
Also, does isomalloc work on that system? My intern from last year told me he never got that to work and always used PUP. While I would assume that the latter would be faster anyway, it would be nice to be able to compare. Thanks!
Rob
From: Kale, Laxmikant V [mailto:kale AT illinois.edu]
Sent: Wednesday, December 07, 2016 2:33 PM
To: Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com>; Chandrasekar, Kavitha <kchndrs2 AT illinois.edu>; White, Samuel T <white67 AT illinois.edu>
Subject: Re: [charm] When to migrate
Rob, Sam can take a look at the application and advice you. Can you tell him what the command line options for your run are?
(He can look at the code in github, I assume) . Kavitha is taking over some of the load balancer work, so I have copied her as well.
Basically either
(a) +MetaLB command line option, and calling AMPI_Migrate() *every* timestep should work, OR
(b) explicitly control it by
1. Start with command line option to shut the instrumentation off to begin with
2. Call AMPI_Load_start_measure(void); right after you have changed the load (up or down step)
3. Call AMPI_Load_stop_measure(void) after K steps (say 4 steps), and call AMPI_Migrate() from every rank right after that
4. Of course, link with load balancers and select the strategy from the command line as before.
Sam, Kavitha, please correct the above if there is any mistake in it.
Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu
Professor, Computer Science kale AT illinois.edu
201 N. Goodwin Avenue Ph: (217) 244-0094
Urbana, IL 61801-2302
From: Van Der Wijngaart Rob F <rob.f.van.der.wijngaart AT intel.com>
Reply-To: Van Der Wijngaart Rob F <rob.f.van.der.wijngaart AT intel.com>
Date: Tuesday, December 6, 2016 at 4:51 PM
To: "Chandrasekar, Kavitha" <kchndrs2 AT illinois.edu>, "White, Samuel T" <white67 AT illinois.edu>
Cc: Phil Miller <unmobile AT gmail.com>, "Totoni, Ehsan" <ehsan.totoni AT intel.com>, "Langer, Akhil" <akhil.langer AT intel.com>, Harshitha Menon <harshitha.menon AT gmail.com>, "charm AT cs.uiuc.edu" <charm AT cs.uiuc.edu>
Subject: RE: [charm] When to migrate
Hi all,
I have been running my code with the placement of the AMPI_Migrate calls as indicated in the figure below. I delay the time of that call between one and five time steps after the load changes, but I see zero effect on performance (this is on a shared memory system, using isomalloc, so the migration does not require serious data transfer). I would expect that with a delay of zero time steps the runtime has no information yet about the changed load, so does not know how to migrate. With one step it knows something, and with a couple more even more. Delaying much longer is no good, because the load will have changed without effective migration executed. So I would expect an initial increase in performance with increasing delay, and subsequently performance decrease if I delay migration even more. The data is noisy, but it is clear migration delay has negligible effect.
I have two questions:
1. How does the runtime actually collect data about load balance? Is it continuous, or only when AMPI_Migrate is called? If the latter, then I’m in trouble, because the runtime would not be utilizing the migration delay to learn more about the load balance.
2. How can I make effective use (if any) of start/stop measurement calls? Should they be used to demarcate a few time steps before a load change occurs, so the runtime can learn?
Thanks!
Rob
From: Van Der Wijngaart, Rob F
Sent: Monday, December 05, 2016 10:28 AM
To: 'Chandrasekar, Kavitha' <kchndrs2 AT illinois.edu>; 'White, Samuel T' <white67 AT illinois.edu>
Cc: 'Phil Miller' <unmobile AT gmail.com>; Totoni, Ehsan <ehsan.totoni AT intel.com>; Langer, Akhil <akhil.langer AT intel.com>; 'Harshitha Menon' <harshitha.menon AT gmail.com>; 'charm AT cs.uiuc.edu' <charm AT cs.uiuc.edu>
Subject: RE: [charm] When to migrate
Hi Kavitha,
One last question. If I have an AMPI code that I have linked with commonLB and that I run with a valid +balancer argument, but I do not call AMPI_Migrate anywhere in the code, does the runtime still collect load balance information? If so, is there a charmrun command that I can give that prevents the runtime from doing that? I know I could use these functions:
AMPI_Load_stop_measure(void)
AMPI_Load_start_measure(void)
but I prefer to specify it on the command line (otherwise I need to supply yet another input parameter and parse it in the code). Thanks!
Rob
From: Van Der Wijngaart, Rob F
Sent: Friday, December 02, 2016 3:19 PM
To: 'Chandrasekar, Kavitha' <kchndrs2 AT illinois.edu>; 'White, Samuel T' <white67 AT illinois.edu>
Cc: 'Phil Miller' <unmobile AT gmail.com>; Totoni, Ehsan <ehsan.totoni AT intel.com>; Langer, Akhil <akhil.langer AT intel.com>; 'Harshitha Menon' <harshitha.menon AT gmail.com>; 'charm AT cs.uiuc.edu' <charm AT cs.uiuc.edu>
Subject: RE: [charm] When to migrate
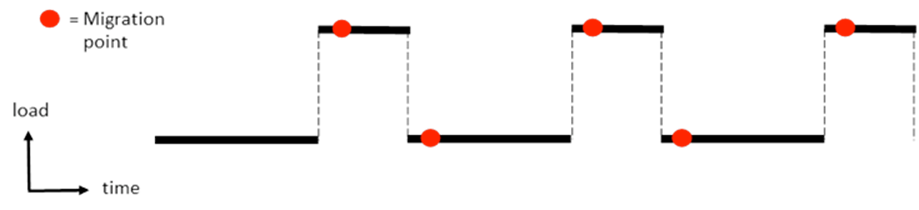
Below is to illustrate how I understood where I should place the AMPI_Migrate calls in my simulation. Is this correct? Thanks!
Rob
![]()
From: Van Der Wijngaart, Rob F
Sent: Friday, December 02, 2016 1:53 PM
To: 'Chandrasekar, Kavitha' <kchndrs2 AT illinois.edu>; White, Samuel T <white67 AT illinois.edu>
Cc: Phil Miller <unmobile AT gmail.com>; Totoni, Ehsan <ehsan.totoni AT intel.com>; Langer, Akhil <akhil.langer AT intel.com>; Harshitha Menon <harshitha.menon AT gmail.com>; charm AT cs.uiuc.edu
Subject: RE: [charm] When to migrate
Thanks, Kavitha, but now I am a little confused. How should I use AMPI_Load_start/stop_measure in conjunction with AMPI+Migrate? Are they only used with the Metabalancer, or also with the fixed balancers? In my case changes in load occur only at discrete points in time; they do not grow or shrink continually. So migration, if done at all, should be done at one of these discrete points, or it will have no effect. If I am supposed to bracket those points with calls to AMPI_Load_start/stop_measure, would the sequence of calls would be something like this: AMPI_Load_start, wait a few time steps for the load to change, AMPI_Migrate, wait a few more time steps, AMPI_Load_stop_measure?
Thanks!
Rob
From: Chandrasekar, Kavitha [mailto:kchndrs2 AT illinois.edu]
Sent: Friday, December 02, 2016 1:10 PM
To: Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com>; White, Samuel T <white67 AT illinois.edu>
Cc: Phil Miller <unmobile AT gmail.com>; Totoni, Ehsan <ehsan.totoni AT intel.com>; Langer, Akhil <akhil.langer AT intel.com>; Harshitha Menon <harshitha.menon AT gmail.com>; charm AT cs.uiuc.edu
Subject: RE: [charm] When to migrate
When using load balancers without Metabalancer, it is sufficient to make the AMPI_Migrate calls when the imbalance appears. Phil pointed out a couple of things regarding this:
1. The AMPI_Migrate calls would need to be placed a few time steps after the imbalance appears, since load imbalance in the ranks would be known to the load balancing framework only at the end of the time step
2. The information supplied to the load balancing framework would be more accurate, if the LB instrumentation is turned off to start with and turned on a few time steps before the load imbalance appears. This can be repeated each time load imbalance occurs.
The calls to turn instrumentation off and on are:
AMPI_Load_stop_measure(void)
AMPI_Load_start_measure(void)
A clarification regarding use of +MetaLB - the option needs to be specified alongside the +balancer <loadbalancer> option.
Thanks,
Kavitha
From: Van Der Wijngaart, Rob F [rob.f.van.der.wijngaart AT intel.com]
Sent: Friday, December 02, 2016 2:20 PM
To: Chandrasekar, Kavitha; White, Samuel T
Cc: Phil Miller; Totoni, Ehsan; Langer, Akhil; Harshitha Menon; charm AT cs.uiuc.edu
Subject: RE: [charm] When to migrateOK, thanks, Kavitha, I’ll do that. Should I apply this method to all load balancers, or only to MetaLB?
Rob
From: Chandrasekar, Kavitha [mailto:kchndrs2 AT illinois.edu]
Sent: Friday, December 02, 2016 12:07 PM
To: Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com>; White, Samuel T <white67 AT illinois.edu>
Cc: Phil Miller <unmobile AT gmail.com>; Totoni, Ehsan <ehsan.totoni AT intel.com>; Langer, Akhil <akhil.langer AT intel.com>; Harshitha Menon <harshitha.menon AT gmail.com>; charm AT cs.uiuc.edu
Subject: RE: [charm] When to migrate
It would be useful to call AMPI_Migrate every few time steps. The load statistics collection happens at the AMPI_Migrate calls. If there is observed load imbalance, which I understand would be when the refinement appears and disappears, then Metabalancer would calculate the load balancing period based on historical data. So, it would be useful to call it more often than only at time step with the load imbalance.
Thanks,
Kavitha
From: Van Der Wijngaart, Rob F [rob.f.van.der.wijngaart AT intel.com]
Sent: Friday, December 02, 2016 1:00 PM
To: Chandrasekar, Kavitha; White, Samuel T
Cc: Phil Miller; Totoni, Ehsan; Langer, Akhil; Harshitha Menon; charm AT cs.uiuc.edu
Subject: RE: [charm] When to migrateHi Kavitha,
After a lot of debugging and switching to the 6.7.1 development version (that fixed the string problem, as you and Sam noted), I can now run my Adaptive MPI code consistently and without fail, both with and without explicit PUP routines (currently on a shared memory system). I haven’t tried the meta load balancer yet, but will do so shortly. I did want to share the structure of my code with you, to make sure I am and will be doing the right thing. This is an Adaptive Mesh Refinement code, in which I intermittently add a new discretization grid (a refinement) to the original grid (AKA background grid). I do this in a very controlled fashion, where I exactly specify the interval (in number of time steps) at which the refinement appears, and how long it is present. This is a cyclical process. Obviously, the amount of work goes up (for some ranks) when a refinement appears, and goes down again when it disappears.
Right now I place an AMPI_Migrate call each time a refinement has just appeared, and when it has just disappeared. So each time I call it something has changed. I have a number of parameters that I vary in my current test suite, including the over-decomposition factor, and the load balancing policy (RefineLB, RefineSwapLB, RefineCommLB, GreedyLB, and GreedyCommLB). I will add MetaLB to that in my next round of tests. My question is if my approach for when to call AMPI_Migrate is correct. Simply put, I only call AMPI_Migrate when the work structure (work assignment to ranks) has changed, and not otherwise. What do you think, should I call it every time step? Note that calling it every so many time steps without regard for when the refinement appears and disappears wouldn’t make much sense. I’d be sampling the workload distribution at a frequency unrelated to the refinement frequency.
Thanks in advance!
Rob
From: Chandrasekar, Kavitha [mailto:kchndrs2 AT illinois.edu]
Sent: Tuesday, November 22, 2016 1:29 PM
To: White, Samuel T <white67 AT illinois.edu>; Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com>
Cc: Phil Miller <unmobile AT gmail.com>; Totoni, Ehsan <ehsan.totoni AT intel.com>; Langer, Akhil <akhil.langer AT intel.com>; Harshitha Menon <harshitha.menon AT gmail.com>; charm AT cs.uiuc.edu
Subject: RE: [charm] When to migrate
The meta-balancer capability to decide when to invoke a load balancer is available with the +MetaLB command line argument. It relies on the AMPI_Migrate calls to collect statistics to decide when to invoke the load balancer. However, in the current release, there is a bug in AMPI_Migrate's string handling, so it might not work correctly.
The meta-balancer capability to select the optimal load balancing strategy is expected to be merged to mainline charm in the near future. I will update the manual to include the usage of meta-balancer.
Thanks,
Kavitha
From: samt.white AT gmail.com [samt.white AT gmail.com] on behalf of Sam White [white67 AT illinois.edu]
Sent: Tuesday, November 22, 2016 3:09 PM
To: Van Der Wijngaart, Rob F
Cc: Phil Miller; Totoni, Ehsan; Langer, Akhil; Harshitha Menon; charm AT cs.uiuc.edu; Chandrasekar, Kavitha
Subject: Re: [charm] When to migrateYes, Kavitha will respond on Metabalancer. MPI_Comm's are int's in AMPI. We should really have APIs in our C and Fortran PUP interfaces to hide these details from users, so thanks for pointing it out.
-Sam
On Tue, Nov 22, 2016 at 3:01 PM, Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com> wrote:
Meanwhile, it would still be great to learn about the status of the meta-balancer. Thanks!
Rob
From: samt.white AT gmail.com [mailto:samt.white AT gmail.com] On Behalf Of Sam White
Sent: Tuesday, November 22, 2016 12:23 PM
To: Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com>
Cc: Phil Miller <unmobile AT gmail.com>; Totoni, Ehsan <ehsan.totoni AT intel.com>; Langer, Akhil <akhil.langer AT intel.com>; Harshitha Menon <harshitha.menon AT gmail.com>; charm AT cs.uiuc.edu; Chandrasekar, Kavitha <kchndrs2 AT illinois.edu>
Subject: Re: [charm] When to migrate
If you are using MPI_Comm_split(), you can completely ignore the text in that section of the AMPI manual. That is specifically in reference to MPI-3's routine MPI_Comm_split_type() [1], which can be used to create subcommunicators per shared-memory node by passing the flag MPI_COMM_TYPE_SHARED. By migrating ranks out of a node, the communicator in this case becomes invalid (the ranks in the communicator no longer share the same address space).
For any other kind of communicator (created via MPI_Comm_dup, MPI_Comm_split, etc.), the user does not need to do anything special before/after calling AMPI_Migrate().
[1] http://www.mpich.org/static/docs/v3.2/www3/MPI_Comm_split_type.html
-Sam
On Tue, Nov 22, 2016 at 2:19 PM, Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com> wrote:
Thanks, Phil! Yeah, my statement about derived communicators was too broad, but in my app I do indeed use MPI_Comm_split to create communicators.
Rob
From: Phil Miller [mailto:unmobile AT gmail.com]
Sent: Tuesday, November 22, 2016 12:17 PM
To: Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com>; White, Samuel T <white67 AT illinois.edu>
Cc: Totoni, Ehsan <ehsan.totoni AT intel.com>; Langer, Akhil <akhil.langer AT intel.com>; Harshitha Menon <harshitha.menon AT gmail.com>; charm AT cs.uiuc.edu; Kavitha Chandrasekar <kchndrs2 AT illinois.edu>
Subject: RE: [charm] When to migrate
Sam should be better able to answer your exact query. Depending on what you need, In brief, that remark in the manual is specifically about MPI_Comm_split_type that's used to get a subcommunicator with physical commonality. It doesn't affect derived communicators in general.
On Nov 22, 2016 2:03 PM, "Van Der Wijngaart, Rob F" <rob.f.van.der.wijngaart AT intel.com> wrote:
Hello Kavitha,
I was just talking with Ehsan and Akhil about logistics of dynamic load balancing in Adaptive MPI applications, see below. Can you give me an update on the status of the meta-balancer? Meanwhile, I ran into a funny issue with my application. I am using MPI_Comm_split to create multiple communicators. This is what I read in the Adaptive MPI manual:
Note that migrating ranks around the cores and nodes of a system can change which ranks share physical resources, such as memory. A consequence of this is that communicators created via MPI_Comm_split_type are invalidated by calls to AMPI_Migrate that result in migration which breaks the semantics of that communicator type. The only valid routine to call on such communicators is MPI_Comm_free .
We also provide callbacks that user code can register with the runtime system to be invoked just before and right after migration: AMPI_Register_about_to_migrate and AMPI_Register_just_migrated respectively. Note that the callbacks are only invoked on those ranks that are about to actually migrate or have just actually migrated.
So is the idea that before a migration I call MPI_Comm_free on derived communicators and reconstitute the communicators after the migration by reinvoking MPI_Comm_split?
Thanks!
Rob
From: Langer, Akhil
Sent: Tuesday, November 22, 2016 10:07 AM
To: Totoni, Ehsan <ehsan.totoni AT intel.com>; Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com>
Subject: Re: When to migrate
I think it is Kavitha Chandrasekar (kchndrs2 AT illinois.edu) who is continuing the work. Harshitha (harshitha.menon AT gmail.com) is now at LLNL.
From: "Totoni, Ehsan" <ehsan.totoni AT intel.com>
Date: Tuesday, November 22, 2016 at 12:03 PM
To: "Van Der Wijngaart, Rob F" <rob.f.van.der.wijngaart AT intel.com>, Akhil Langer <akhil.langer AT intel.com>
Subject: RE: When to migrate
The person working on it (Harshitha) has left recently and I don’t know who picked up the work. I suggest sending an email to the mailing list. Hopefully, the meta-balancer is in a usable shape.
-Ehsan
From: Van Der Wijngaart, Rob F
Sent: Tuesday, November 22, 2016 9:33 AM
To: Totoni, Ehsan <ehsan.totoni AT intel.com>; Langer, Akhil <akhil.langer AT intel.com>
Subject: RE: When to migrate
Thanks, Ehsan! Indeed, my workload is iterative. The structure is as follows:
for (t=0; t<T; t++) {
if (iter%period<duration && criterion(my_rank) do extra work;
do regular work;
}
So whenever the time step is a multiple of the period, some ranks (depending on the criterion function) start doing extra work for duration steps. As you can see, there is a hierarchy in the iterative workload behavior.
Whom should I contact about the meta-balancer?
Thanks again!
Rob
From: Totoni, Ehsan
Sent: Tuesday, November 22, 2016 9:24 AM
To: Van Der Wijngaart, Rob F <rob.f.van.der.wijngaart AT intel.com>; Langer, Akhil <akhil.langer AT intel.com>
Subject: RE: When to migrate
Hi Rob,
If the workload is iterative, where in the iteration AMPI_Migrate() is called shouldn’t matter in principle for measurement-based load balancing. Of course, there are tricky cases where this doesn’t work (few long variant iterations etc). There is also a meta-balancer that automatically decides how often load balancing should be invoked and which load balancer. I can’t find it in the manual so I suggest sending them an email to make them document it J
Is your workload different than typical iterative applications?
Best,
Ehsan
p.s. MPI_Migrate() is renamed to AMPI_Migrate(). MPI_ prefix is not used anymore for AMPI-specific calls.
From: Van Der Wijngaart, Rob F
Sent: Tuesday, November 22, 2016 9:01 AM
To: Langer, Akhil <akhil.langer AT intel.com>; Totoni, Ehsan <ehsan.totoni AT intel.com>
Subject: When to migrate
Hi Akhil and Ehsan,
I have a silly question. I put together a workload designed to test the capabilities of runtimes to do dynamic load balancing. It’s a very controlled environment. For a while nothing happens to the load, but at discrete points in time I either remove work from or add work to an MPI rank (depending on the strategy chosen, this could be quite dramatic, such as a rank having no work to do at all for a while, then it gets a chore, and after a while stops doing that chore again). I am adding PUP routines and migrate calls to the workload to test it using Adaptive MPI. The question is when I should invoke MPI_Migrate. Should I do it just before the load per rank changes, or right after? Because the period during which I add or remove work from a rank could be short, this could make quite a difference. The workload is cyclic, so the runtime can learn, in principle, from load changes in the past.
Thanks for any advice you can offer!
Rob
- RE: [charm] When to migrate, (continued)
- RE: [charm] When to migrate, Chandrasekar, Kavitha, 12/02/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/02/2016
- RE: [charm] When to migrate, Chandrasekar, Kavitha, 12/02/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/02/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/02/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/05/2016
- Re: [charm] When to migrate, Phil Miller, 12/05/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/05/2016
- Re: [charm] When to migrate, Phil Miller, 12/05/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/06/2016
- Message not available
- Message not available
- Message not available
- Message not available
- Message not available
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/21/2016
- Message not available
- Message not available
- RE: [charm] When to migrate, Chandrasekar, Kavitha, 12/02/2016
- Message not available
- Message not available
- Message not available
- Message not available
- Message not available
- Message not available
- Re: [charm] When to migrate, Sam White, 12/21/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/21/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/22/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/22/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/22/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/22/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/23/2016
- Message not available
- Re: [charm] When to migrate, Sam White, 12/23/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/23/2016
- Message not available
- Re: [charm] When to migrate, Sam White, 12/23/2016
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/23/2016
- Message not available
- RE: [charm] When to migrate, Van Der Wijngaart, Rob F, 12/02/2016
- RE: [charm] When to migrate, Chandrasekar, Kavitha, 12/02/2016
Archive powered by MHonArc 2.6.19.